渗透测试中的信息搜集
目标网站如果用了 CDN 技术,对于安全测试是有阻碍的,必须想办法绕过,不然测试意义不大。
查看目标网站是否用了 CDN 技术,可以超级 ping 一下,看响应 IP 是否都一样。
CDN 绕过方法:
子域名查询。如 computer.xxx.edu.cn 和 www.xxx.edu.cn 是同一个 IP,即使不是同一个 IP ,也可能在同一个网段。此时扫一下存活 IP 或爆一下网段,及扫一下 IP 对应开放端口,就可能找到主站真实 IP 。
邮件服务查询。因为外部用户对邮件服务一般访问较少,多为公司内部使用,所以架设 CDN 的可能性不大。但是有可能采用了反向代理技术,即你主动去访问它,可能访问到的只是一个代理。应该让它主动访问你,比如给你发一个邮件,那么就可能暴露该网站的真实 IP 。
网页端打开它发过来的邮件,右键查看邮件源码,在里面找 IP 。如果你不确定这个是不是主站真实 IP (有可能跟你用其他方法如
ping xxx.com得到的 IP 不一样),那社工一下。查一下 IP 所在区域,再对比网站备案地址、公司所在位置,地点相近的那个 IP 可能性更大。国外地址请求。有的网站主要用户群体在国内,所以可能针对国外就没有架设 CDN 了。如果用一个国外的地址去访问,就可能得到网站的真实 IP 。
遗留文件。如某些用 PHP 写的网站,可能存在 phpinfo.php 这类信息文件,且可以访问,那么里面的 IP 可能就是网站的真实 IP 。

inurl:phpinfo.php 。
- DDoS 。两种方法:
- 收集所有响应 IP ,可能里面就存在真实 IP 。因为可能有些请求就在主机旁边,其响应由主机发出。
- DDoS 一个 CDN ,当这个 CDN 的流量挂了,真实 IP 就暴露了。
- DNS 历史记录。有的站可能在一开始没有架设 CDN ,后来因为访问量变大而架设 CDN ,所以查 DNS 历史记录就可能查得到真实 IP 。
获取到真实 IP 后,修改本地 hosts 文件,就可以永久绕过 CDN 。
大部分网站加或不加 www 访问时,都会访问到同一个网页。如 baidu.com 和 www.baidu.com ,即 www 对应的那个网页。
但是如果该网站架设了 CDN ,那么这两种方式对应的 IP 是不一样的,如百度:
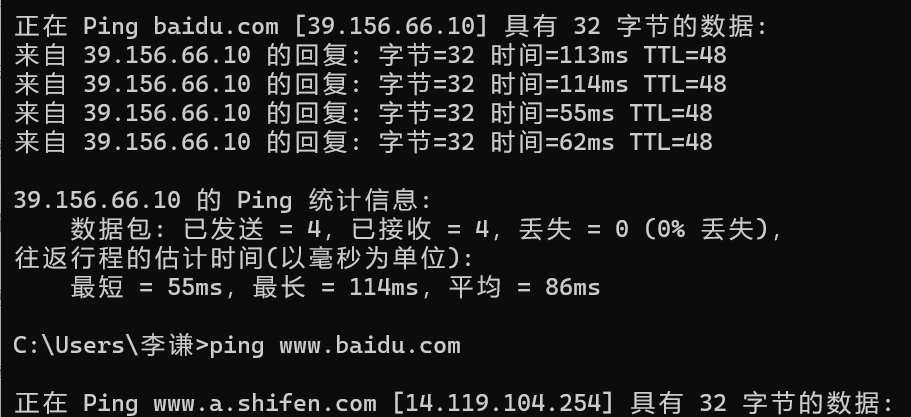
因为一般用户访问时都会加上 www ,但为了访问的便利性和网站的一般设置,会设置如下:

但是一般只有主站会这么设置,CDN 站就只有 www 而没有 * 。
所以一般不加 www 的那个 url 的 IP 就是主站 IP 。
一般 m.xxx.com 是手机访问时站点,如 m.baidu.com 。
信息搜集要完成的任务:
有无 CDN 。
编程语言、框架类型或 CMS 类型。
操作系统、搭建平台类型(如PHPStudy)、数据库类型。
一般用第三方搭建平台(PHPStudy、宝塔等)管理站点的,响应包中 Server 字段的内容是比较多的,如
Server: Apache/2.4.23 (Win32) OpenSSL/1.0.2j PHP/5.4.45。如果是自己下载 Apache、Nginx 等中间件,自己搭建的网站,就不会这么全。有无 WAF ,有 WAF 的一般响应包里会带
X-Powered-By: [xxx]WAF[xxx]字段。先看有没有 WAF 再扫,直接开扫会被 WAF 封锁 IP 。
一般封 IP 是因为网站识别到你是爬虫程序(UA头判别),所以你可以修改 UA 为官方浏览器的爬虫来绕过。当然如果是针对异常流量封 IP ,那就没办法了。
子域名搜集、顶级域名搜集、IP 收集、目录扫描、端口扫描。
可能该站换过顶级域名,或同时备案了其他顶级域名,如
www.baidu.org、www.baidu.net。社工。
在信息搜集的过程中,要敏锐嗅探,总是询问“这个地方是否可能存在漏洞”。
根据关键字进行信息搜集,如网站关键字、xxx 公司、xxx 产品。
目录扫描,用工具开扫的话,一般会被 waf 拦截。原因:
- 工具发送的请求包的请求方式一般不是 GET 或 POST ,而是响应更快的 HEAD 等,这不符合一般用户使用浏览器的访问习惯。
- 工具发送请求包的速度很快,不符合一般用户使用浏览器的访问速度。
绕过思路一般就是围绕这两点展开。绕过方法:
- 修改请求方式。
- 延时请求。效率很低,不得已的方法。
- 修改请求数据包,模拟用户使用浏览器发送的请求。工具的请求包跟浏览器是不一样的,有一些字段没有, UA 头也不一样,所以可根据浏览器的请求包自定义工具的请求包,模拟浏览器发送的请求。
- 如果第三种方法由于工具灵活性不高而无法完全自定义,那就写脚本实现。
对于第三和第四种方法,请求包的 UA 头的值可以有两种:浏览器的 UA 头和爬虫引擎。
如果用浏览器的 UA 头,在不使用延时请求的情况下,也会有因为不符合用户访问速度而被拦截的可能,而如果改成官方的爬虫引擎,如百度的爬虫、360 的爬虫,就可以解决这个问题。
- 写脚本+代理池 。爬取网上可用的代理池的 IP ,整合为代理字典,每一个代理发几个包。
有时候字典也会被 waf 拦截,如请求备份文件、普通用户不可能访问的文件。waf 识别出此 IP 想请求这些文件,然后进行拦截。这种情况的绕过跟绕文件上传黑名单一样。安全都是相通的,主要是掌握思路并融会贯通。
如果是违法网站,可能会经常换域名,但一般标题、关键字这些不会换。此时可以 Google Hack ,搜集更多相关站点。
旁注:同服务器(即同 IP )不同站点。如 1.1.1.1 下 www.a.com 和 www.b.com 。
C 段:同网段不同服务器不同站点。如 1.1.1.1 下 www.a.com 和 www.b.com ,1.1.1.2 下 www.c.com 和 www.d.com 。
旁注和 C 段都是目标站点攻击不下时,不得已的策略。
社工渠道:微信公众号、微信群、QQ群、钉钉群等。混入其中,伪装身份套取信息。
学会工具的联动,比如某 waf 封 Xray ,但不封 AWVS ,但是又想用 Xray ,则可以 AWVS - Burp - Xray 联动:AWVS 扫 - Burp 拦截 - 转发到 7070 端口 - Xray 监听 7070 端口。